|
Fujitsu Develops Platform Technology to Support High Speed Processing of Massive Data in Distributed Storage
Overall system performance enhanced by greater applications for distributed storage
TOKYO, Sep 20, 2018 - (JCN Newswire) - Fujitsu Laboratories Ltd. has developed a technology that offers both high speed data-processing and high-capacity storage in distributed storage systems, in order to speed up the processing of ever-increasing volumes of data.
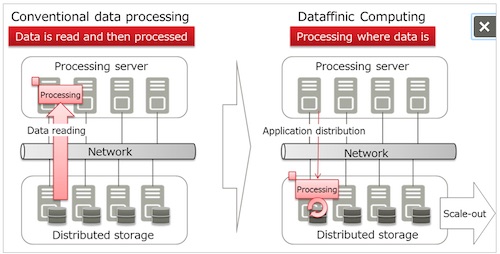 | | Figure 1: Data processing with Dataffinic Computing | | |
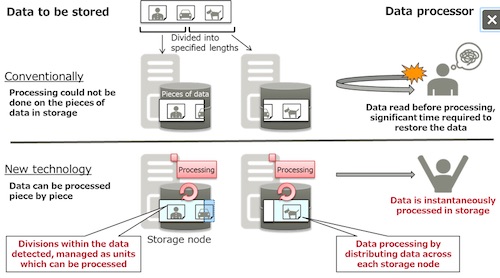 | | Figure 2: Storage and processing of unstructured data | | |
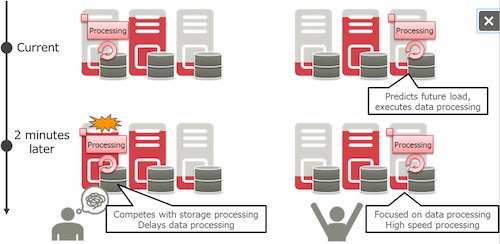 | | Figure 3: Technology that predicts necessary resources and controls resources for data processing | | |
Recently, customers have looked for improvements in processing speed in storage systems that handle everything up to data analysis. This is in response to a growing need in such technologies as AI and machine learning for the analysis and utilization of rapidly growing volumes of data, including unstructured data, such as video and log data. However, this requires storage systems that can efficiently analyze unstructured data stored in a distributed system, while providing their original storage functionality for data management as well as data processing capabilities. Fujitsu Laboratories has now developed "Dataffinic Computing," a technology for distributed storage systems that handles data processing while also fulfilling their original storage function, in order to speed up the processing of large volumes of data. With this technology, storage systems can process large volumes of data at high speeds, including unstructured data, enabling the efficient utilization of the ever-increasing amounts of data, in such cases as utilizing security camera video, analyzing logs from ICT systems, utilizing sensor data from cars, and analyzing genetic data.
Development Background
Currently, there is a developing trend of innovation and business transformation through the utilization of large volumes of data generated on various front lines. The volume of data is increasing exponentially as there are conventional structured data managed in a database, such as customer data and POS data, as well as unstructured data, such as video and log data. To efficiently use this large volume of data, AI, machine learning and other technologies are in demand to streamline analysis. Conventionally, data was analyzed in processing servers, but if data could be processed in the same systems where it is stored, it is expected that would increase the speed of data analysis processing.
Issues
Data processing requires the processing server to read the data from the storage system. As the volume of data flowing between the storage system and the processing server increases, the time required to read the data can become a bottleneck when utilizing large volumes of data. On the other hand, data processing at high speeds becomes possible when the processing is done on the storage system without moving the data. Nonetheless, this makes it difficult to analyze unstructured data distributed across the storage system, and to maintain stable operations in the system's original storage functionality.
About the Newly Developed Technology
Fujitsu Laboratories has developed Dataffinic Computing, a technology for handling data processing in distributed storage systems that distributes and collects data by connecting multiple servers through a network, without reducing the original storage functionality of the system, in order to rapidly process ever increasing volumes of data. Details of the newly developed technology are as follows.
http://www.acnnewswire.com/topimg/Low_FujitsuDataProcessingFig1.jpg
Figure 1: Data processing with Dataffinic Computing
1. Content-aware data disposition that can process each distributed data items
In order to improve access performance, distributed storage systems do not store large amounts of data in the same place, but break the data into sizes that are easy to manage for storage. In the case of unstructured data such as videos and log data, however, individual pieces of data cannot be completely processed when the file is systematically broken down into pieces of specified size and stored separately. It was therefore necessary to once again gather together the distributed data for processing, placing a significant load on the system. Now, by breaking down unstructured data along natural breaks in the connections within the data, this technology stores the data in a state in which the individual pieces can still be processed. In addition, information essential for processing (such as header information) is attached to each piece of data. This means that the pieces of data scattered across the distributed storage can be processed individually, maintaining the scalability of access performance and improving the system performance as a whole.
http://www.acnnewswire.com/topimg/Low_FujitsuDataProcessingFig2.jpg
Figure 2: Storage and processing of unstructured data
2. Adaptive resource control with storage functionality and data-processing capability
In addition to the ordinary reading and writing of data, storage nodes face a variety of system loads to safely maintain data, including automatic recovery processing after an error, data redistribution processing after more storage capacity is added, and disk checking processing as part of preventive maintenance. This technology models the types of system loads that occur in storage systems, predicting resources that will be needed in the near future. Based on this, the technology controls data processing resources and their allocation, so as not to reduce the performance of the system's storage functionality. This enables high speed data processing while still delivering stable operations for the original storage functionality.
http://www.acnnewswire.com/topimg/Low_FujitsuDataProcessingFig3%20.jpg
Figure 3: Technology that predicts necessary resources and controls resources for data processing
Effects
Fujitsu Laboratories implemented this technology in Ceph(1), an open source distributed storage software solution, and evaluated its effects. Five storage nodes and five processing servers were connected with a 1 Gbps network, and data processing performance was measured when extracting objects such as people and cars from 50 GB of video data. With the conventional method, it took 500 seconds to complete processing, but with this newly developed technology, the data processing could be done on the storage nodes, without the need to bring the data together. Moreover, the processing was completed in 50 seconds, 10 times the speed of the previous method. This technology enables scalable and efficient processing of explosively increasing amounts of data.
Future Plans
Fujitsu Laboratories will continue to verify this technology for commercial applications, planning for Fujitsu Limited to make it into a product within fiscal 2019.
(1) Ceph Open source distributed storage software now managed by the Ceph community, which was originally developed by the University of California, Santa Cruz, before 2004.
About Fujitsu Laboratories
Founded in 1968 as a wholly owned subsidiary of Fujitsu Limited, Fujitsu Laboratories Ltd. is one of the premier research centers in the world. With a global network of laboratories in Japan, China, the United States and Europe, the organization conducts a wide range of basic and applied research in the areas of Next-generation Services, Computer Servers, Networks, Electronic Devices and Advanced Materials. For more information, please see: http://www.fujitsu.com/jp/group/labs/en/.
Contact:Fujitsu Laboratories Ltd.
Computer Systems Laboratory
E-mail: dataffinic@ml.labs.fujitsu.com
Fujitsu Limited
Public and Investor Relations
Tel: +81-3-3215-5259
URL: www.fujitsu.com/global/news/contacts/
Source: Fujitsu Ltd
Sectors: Electronics, Cloud & Enterprise
Copyright ©2024 JCN Newswire. All rights reserved. A division of Japan Corporate News Network. |